
Existe evidência de fraude nas eleições presidenciais brasileiras de 1994 a 2018?
By Neale Ahmed El-Dash on Nov 22, 2019
Nesse post discutiremos se há evidência estatística de fraude nas eleições presidenciais brasileiras, entre os anos de 1994 a 2018. Para isso serão aplicadas duas técnicas estatísticas comummente utilizadas para detecção de fraudes em eleições : a Lei de Benford e o gráfico da impressão digital.
Introdução
Nas últimas semanas escrevi dois posts (post1 e post2) sobre a possível fraude nas eleições presidenciais bolivianas de 2019. Discutir esse tema me deixou curioso sobre o caso brasileiro. Será que elas apresentam alguma anomalia estatística que pode ser um indício de fraude?
Existem dois indicadores estatísticos comummente utilizados para detectar fraude eleitoral: gráfico da Impressão digital e a Lei de Benford. Cada um deles baseia-se em princípios e suposiçoes diferentes. Neste post discutirei em mais detalhes a Lei de Benford, pois o gráfico da Impressão digital já foi discutido nesse post.
Dados do TSE
Os dados dos resultados das eleições brasileiras foram obtidos no repositório de dados eleitorais, do Tribunal Superior Eleitoral (TSE). De acordo com o próprio site, os dados dos anos de 1994 a 2002 estão incompletos, pois está sendo realizada uma revisão nas fontes dos dados. Na análise realizada aqui usaremos também também os dados incompletos, pois o fato de dados serem incompletos poderia ser detectado como fraude pelos indicadores estatísticos, algo que mostraria tanto a utilidade dos mesmos quanto a necessidade de cautela ao utilizar técnicas estatísticas para detectar fraudes eleitorais.
Os indicadores de fraude
Os métodos estatísticos para detectar fraudes geralmente identificam anomalias nos resultados das eleições que poderiam ter sido causadas por fraudes eleitorais. A eficiência desses métodos depende do tipo de fraude cometida, pois as anomalias resultantes são diferentes. Nas próximas seções discutiremos dois indicadores estatísticos de fraude eleitoral: o gráfico da impressão digital e a Lei de Benford.
O gráfico da impressão digital
O método do gráfico da impressão digital analisa a distribuição de votos e o comparecimento dos eleitores. Esse indicador recebe o nome porque o gráfico resultante parece uma impressão digital. Dois tipos de fraude podem ser detectadas utilizando este tipo de análise: a adição de votos falsos para um candidato nas urnas e a substituição dos votos de um candidato para outro. Esses mecanismos de fraude produzem algumas características peculiares nos resultados das eleições, características essas que dificilmente ocorrem em eleições justas.
A fraude de adicionar votos em urnas pode ser incremental ou extrema: poucos votos para o candidato beneficiado adicionados a muitas urnas, ou muitos votos adicionados a poucas urnas, respectivamente. Geralmente a opção por qual estratégia adotar para fraudar resultadps está relacionada a questões logísticas. Por um lado, espalhar os votos fraudulentos em mais locais pode ser menos óbvio, porém necessita do envolvimento de mais conspiradores. Concentrar os votos em menos locais pode gerar anomalias mais evidentes, porém potencialmente produz menos testemunhas. Como o limite de votos a ser adicionado numa urna é o total de eleitores registrados naquele local, estas fraudes induzem uma correlação forte entre o percentual de votos do candidato ganhador e o percentual de comparecimento de eleitores. No gráfico da impressão digital, essa carrelação faz parecer que os pontos são atraídos para o canto superior direto. Esse artigo (Klimek et al. 2012) discute em detalhes análises estatísticas que podem ser realizadas para detectar estas fraudes, e compara os resultados de eleições em diferentes países com o objetivo de identificar fraudes eleitorais.
É possível detectar essas anomalias em eleições sem fraude. Em áreas muito pequenas, elas podem ocorrer naturalmente, com a quase totalidade dos votos favoráveis ao vencedor ou abstencão quase nula. Entretanto, quanto mais eleitores forem registrados num local, mais raro é que o local apresente essas anomalias. Em locais maiores, com mais de 100 eleitores, é difícil acontecer que todos os eleitores compareçam e votem no mesmo candidato.
Esta característica foi procurada no resultados da votação do Brasil. A análise foi realizada no nível das seções eleitorais, as quais têm, em média, de 345 eleitores cadastrados e 278 votos computados. Adotamos aqui a estratégia de retirar da análise locais com menos de 100 eleitores registrados para reduzir a probabilidade de observar a anomalia discutida aqui.
A análise apresentada nesse post é meramente exploratória, procurando identificar seções eleitorais com as anomalias descritas acima: alto percentual de voto para o candidato vencedor, e alto percentual de comparecimento. Na figura 1 mostramos os resultados para todas as seções eleitorais para os anos de 1994 a 2018. Não parece haver evidência de fraude, pois em nenhuma das eleições é possível identificar grupos de seções eleitorais que parecem estar sendo “atraídas” para o canto superior direito do gráfico.
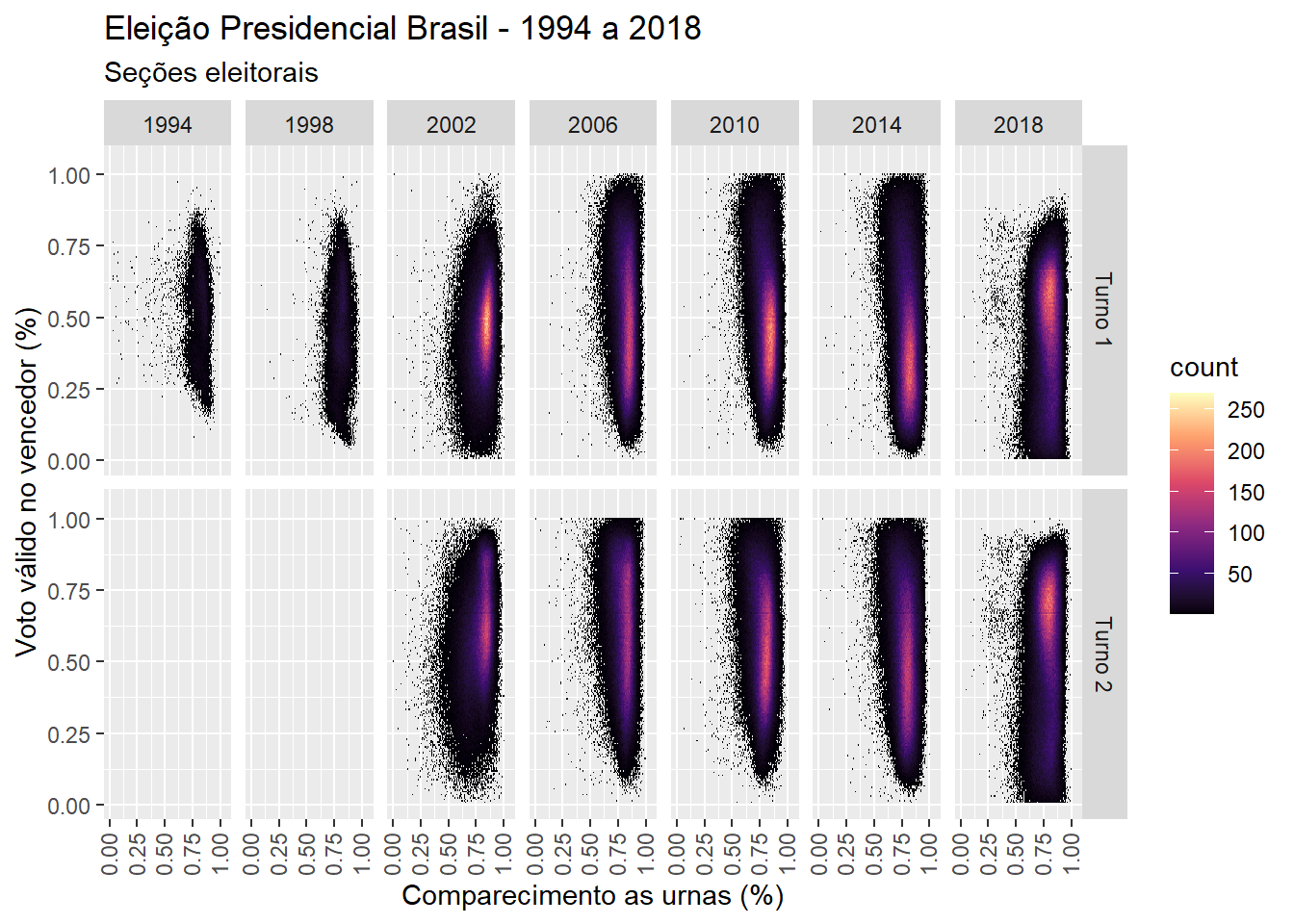
Figure 1: Gráfico mostrando a relação entre comparecimento as urnas e voto válido
Gráfico Fingerprint
No código abaixo, os dados são consolidados por sessão eleitoral. Apesar do código estar pronto, não incluirei os dados para download no site pois não há espaço no servidor para um arquivo de 78 megas. Se houver o interesse em obter os dados, entre em contato pelo email no site.
require(tidyverse)
dir = tempdir()
#código baixando os dados do site do PollingData
#o arquivo df_94_18.rds não foi disponibilizado no site
url <- "http://www.pollingdata.com.br/blog/fraude eleitoral bolivia - 10-23-2019/df_94_18.rds"
file.data = tempfile(tmpdir=dir, fileext=".rds")
download.file(url,file.data,method="curl")
df.finger <- readRDS(file.data)
df.finger <- df.finger %>% filter(pop >= 100)
gg <- ggplot(data=df.finger) +
geom_bin2d(aes(x=turnout,y=winner),bins = 200) +
facet_grid(turno~ano) +
#geom_abline(slope=1, intercept=0,colour="red",size=0.5) +
scale_fill_viridis_c(option = "A")
gg <- gg + xlim(c(0,1.05)) + ylim(c(0,1.05))
gg <- gg + labs(title = "Eleição Presidencial Brasil - 1994 a 2018", subtitle="Seções eleitorais") +
ylab("Voto válido no vencedor (%)") + xlab("Comparecimento as urnas (%)")
gg <- gg + theme(axis.text.x = element_text(angle = 90, vjust=0.4))
ggA lei de Benford
A lei de Benford se refere ao comportamento de números aleatórios encontrados na natureza, onde é mais provável encontrar números começando com dígitos menores do que maiores. Por exemplo, espera-se encontrar 30,1% dos números iniciando-se com o dígito 1, e apenas 4,6% com o dígito 9. Em 1938, um artigo foi publicado sobre o tema pela físico Frank Benford1 e por isso recebeu esse nome. Nesse artigo apontou que a probabilidade de encontrar números aleatórios na natureza iniciados com qualquer dígito d, entre 1 e 9, é dada por \(P(dígito\ inicial\ =\ d) = \log_{10}\left(\frac{d+1}{d}\right)\). Na tabela 1, calculamos esta probabilidade para todos os dígitos. A lei de Benford intrigou muitos cientistas por anos, parecendo uma lei misteriosa da natureza. Uma explicação técnica, porém bem intuitiva, da lei é apresentada no artigo de (Fewster 2009).
| Dígito (d) | Probabilidade |
|---|---|
| 1 | 30.1 |
| 2 | 17.6 |
| 3 | 12.5 |
| 4 | 9.7 |
| 5 | 7.9 |
| 6 | 6.7 |
| 7 | 5.8 |
| 8 | 5.1 |
| 9 | 4.6 |
Gráfico Fingerprint
No código abaixo, calculamos as probabilidades esperadas de números que têm o primeiro dígito \(d={1,2,...,9}\) de acordo com a Lei de Benford.
df <- tibble(
d = 1:9,
prob = round(100*log((d+1)/d,base=10),1)
)
names(df) <- c('Dígito (d)','Probabilidade')
knitr::kable(df,
align=rep('c', ncol(df)),
escape = FALSE,
booktabs = TRUE,
caption = 'Probabilidade de um número ter o dígito inicial d.') %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),full_width = F, position = "center")De fato, essa lei não é intuitiva. Detalhes mais técnicos sobre como a lei pode ser provada podem ser vistos clicando no botão “Mostrar Código” abaixo. No texto principal deste post, entretando, somente discutirei superficialmente quando a lei é válida e sob quais condições. A lei de Benford se aplica a números inteiros, positivos. Para que a lei seja aplicável a um conjunto de números (a amostra), os dados devem respeitar uma condição: eles têm que ter sido gerados por um processo onde apenas números inteiros positivos possam ocorrer. Não é necessário que todos os números tenham a mesma chance de ocorrer; basta que números de diferentes ordens de grandeza ocorram. Essa condição versa sobre o processo gerador dos números sendo analisados, o qual geralmente é desconhecido.
Lei de Benford
Para entender a Lei de Benford, o primeiro passo transformar os números inteiros positivos, a qual ela se refere, em números científicos. Utilizando essa notação, temos que um número \(X \in \mathbb{Z}^{+}\), pode ser representado de forma única por:
\[\begin{equation} \label{eq:cient} X = r \times 10^{n}, \tag{1} \end{equation}\]
onde \(1 \leq r < 10\) é um número real e \(n\) é um número inteiro. Note que \(r\) está definido em (1) entre 1 e 9. Não existe a necessidade de \(r \geq 10\) porque bastaria aumentar o \(n\) em uma unidade. Utilizando essa notação, o número \(135\ =\ 1,35 \times 10^{2}\), por exemplo.
A vantagem de utilizar a notação científica nesse contexto é que facilita racionalizar o problema. Com a notação usual, os números inteiros positivos com primeiro digito 1 são o 1, depois todos os números entre 10 e 19, depois todos entre 100 e 199, entre 1000 a 1999, entre 10000 a 19999, e assim por diante. Porém utilizando a notação científica, para qualquer \(n\), os números inteiros positivos com primeiro digito \(d\), com \(d \in {1,2,...,9}\), são todos aqueles onde \(d \leq r < d+1\). Para ver isso, basta notar que primeiro dígito do número \(X\) é igual a parte inteira do número \(r\). Por exemplo, o primeiro dígito de \(X\) será 1 somente quando \(1 \leq r < 2\).
Ou seja, os intervalos de todos os números inteiros positivos com primeiro dígito \(d\) são determinados por \(log_{10}(d)+n \leq log_{10}(X) < log_{10}(d+1)+n\), pois sabemos que \(log_{10}(X)=log_{10}(r)+n\). Para ser didático, vamos analisar o caso com \(d=1\). Nesse caso, sabemos que um número inteiro positivo terá o primeiro dígito 1 se \(1 \leq r < 2\), para qualquer \(n\). O que equivale a dizer que um número terá o primeiro dígito 1 se \(n \leq log_{10}(X) < 0.30103 + n\), para qualquer \(n\).
Podemos interpretar o número \(n\) como a ordem de grandeza do número, pois indica a qual potência do número 10. Note que independentemente da ordem de grandeza, o tamanho do intervalo dos números que têm o primeiro dígito \(d\) é sempre igual a:
\[log_{10}(d+1)+n - log_{10}(d)+n = log_{10}(\frac{d+1}{d})\].
A importância desse resultado é que ele indica o comprimento do suporte da distribuição de \(log_{10}(X)\) que pertencerá a cada grupo de números com o primeiro dígito em comum. Se essa distribuição fosse uniforme, seria fácil ver que a probabilidade do primeiro dígito ser \(d\) seria dado por esse intervalo. Porém a distribuição empírica de \(log_{10}(X)\) será diferente para cada conjunto de dados analisado. Por exemplo, na figura 2 mostramos os votos que o candidato Bolsonaro obteve em cada município do Brasil no primeiro turno da eleição de 2018. As ordens de grandeza (n) foram destacadas no topo do gráfico, e as cores indicam qual é o primeiro dígito daquele intervalo de votos. Note que a quantidade de observações em cada faixa da escala \(log_{10}\) têm um comportamento diferente, nenhum dos quais se assemelha a distribuição uniforme.
df.sim <- df.benford %>% filter(ano==2018,turno==1) %>% select(-votos) %>% gather(cand,votos,starts_with('votos_'))
df.sim$log <- log(df.sim$votos,base=10)
df.sim$n <- floor(df.sim$log)
df.sim$r <- df.sim$log - df.sim$n
df.sim$digito <- as.numeric(str_sub(df.sim$votos,1,1))
df.sim$start <- map_dbl(df.sim$digito,~log(.,base=10))
df.sim$end <- map_dbl(df.sim$digito,~log(.+1,base=10))
df.sim$digito <- as.character(df.sim$digito)
df.sim$width <- df.sim$end - df.sim$start
df.sim$center <- df.sim$width / 2
df.sim$breaks <- df.sim$n + df.sim$end
df.sim$x <- df.sim$n + df.sim$start + df.sim$center
df.sim <- df.sim %>% group_by(x,n,digito,width,center,breaks) %>% count(name="y")
df.sim <- df.sim %>% drop_na()
df.sim <- df.sim %>% filter(n >= 1)
df.sim$pop <- 10^(df.sim$x)
breaks.label <- round(unique(df.sim$breaks),2)
breaks.pos <- unique(df.sim$x)
g1 <- ggplot(df.sim, aes(x=x, y=y, width=width))
g1 <- g1 + geom_bar(aes(fill=digito), stat="identity", position="identity")
g1 <- g1 + facet_grid(.~n,scales="free_x",space="free_x")
g1 <- g1 + scale_x_continuous(breaks=breaks.pos,labels = breaks.label)
#g1 <- g1 + scale_x_continuous("Ordem de grandeza(n)", breaks=1:7, limits=c(1,7))
g1 <- g1 + theme(axis.text.x = element_text(angle = 90, vjust=0.4,size = 6),
panel.margin = unit(0.1, "lines"))
g1 <- g1 + labs(x=expression(Log[10](voto)),y="Freqüência")
g1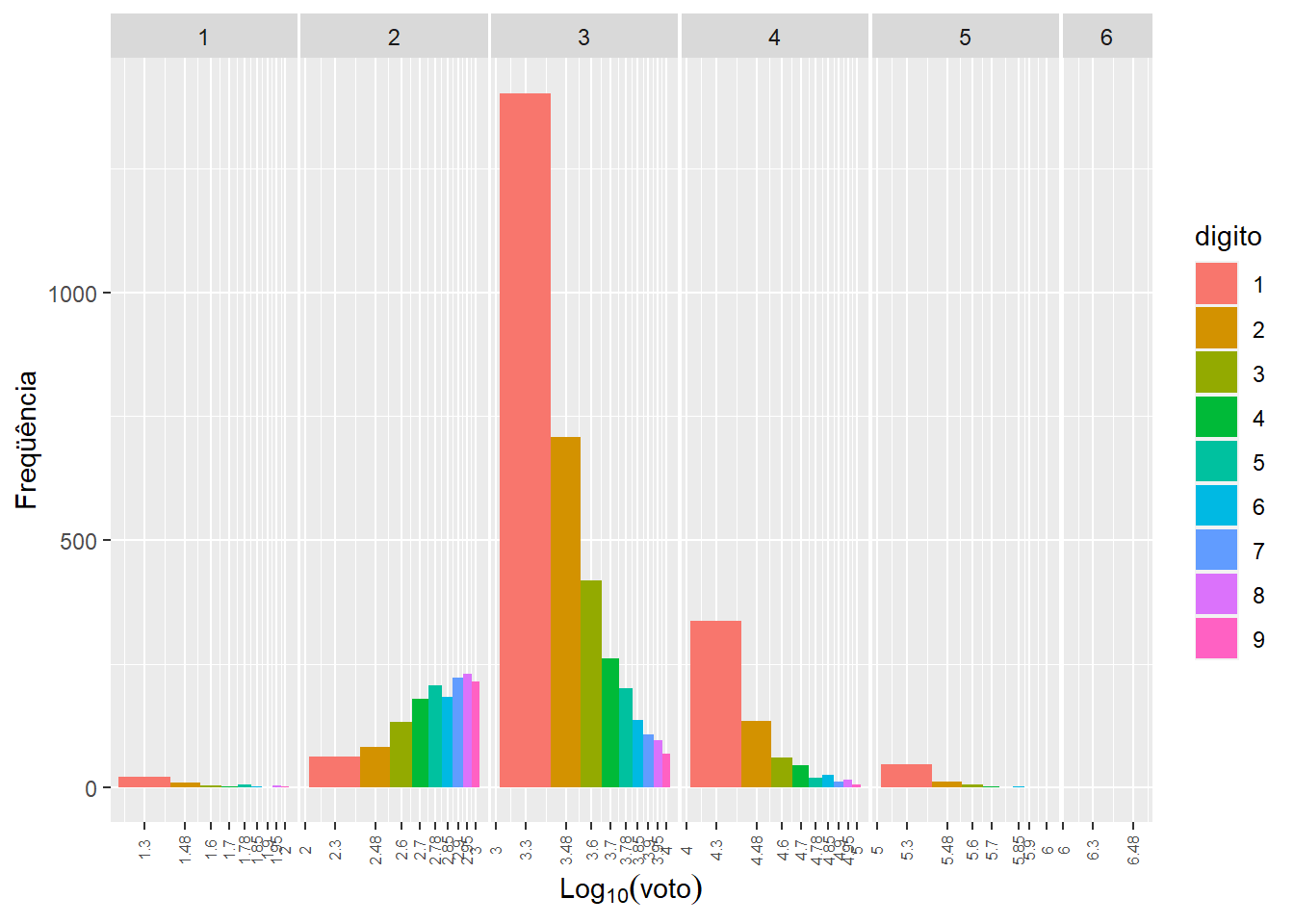
Figure 2: Gráfico mostrando intervalos dos números com primeiro dígito d
Nesse contexto, é possível afirmar qual será a probablidade de um número X ter o primeiro dígito d? Sim, porém argumentos assintôticos têm que ser utilizados, de maneira similar aos argumentos utilizados para calcular a integral de Riemann de uma função, ou a área sob uma curva. Para calcular a área sob uma curva, somam-se retângulos com a mesma largura em todo o suporte da função. No limite, onde a largura de cada retângulo vai para zero e o número total de retângulos vai para o infinito, essa soma infinita será igual a área sob a curva.
Imagine agora utilizaremos essa mesma lógica, porém agora vamos pintar cada retângulo, alternadamente, de preto e branco. Se a função for constante, mesmo se ouverem poucos retângulos largos, metade da área sob a curva será preta e metade branca. Porém, ao utilizar poucos retângulos largos para “pintar” outras formas de funções não garantirá que metade da área seja de cada cor. Se reduzirmos a largura dos retângulos e aumentarmos a quantidade deles, percorrendo todo o suporte da função, qualquer função razoavelmente bem comportada terá sua área pintada 50% branca e 50% preta. Ou seja, a proporção do suporte pintada de branco será reproduzido na área total sob a curva. Se pintarmos 80% dos retângulos de branco, então 80% da área sob a função será branca.
No caso discutido aqui dos números com o primeiro dígito d, sabemos qual o percentual do suporte da distribuição empírica de \(log_{10}(X)\) pertencerá a qual primeiro dígito. Mas nesse caso não é possível reduzir a largura dos retângulos que representam cada dígito d, pois eles têm larguras fixas determinadas por \(log_{10}(\frac{d+1}{d})\). A alternativa é supor que o suporte da função será de \((0,\infty)\), porque nesse caso teríamos infinitos retângulos com uma largura bem pequena. Por isso que para a Lei de Benford ser válida é preciso supor que os números considerados percorrem muitas ordens de grandeza. Em termos práticos, números que cheguem a ordem de \(10^{7}\) são suficientes.
Pelo mesmo motivo também é necessária uma sequência grande de números, para que a aproximação seja progressivamente melhor. Os números utilizados para calcular o primeiro dígito podem ser definidos de muitas formas diferentes. No exemplo do post consideramos apenas o voto no vencedor, porém poderíamos considerar o voto em todos os candidatos. Dessa forma o tamanho total da amostra seria bem maior, porém a amplitude dos dados não seria alterada, então não há garantia de que a aproximação pela Lei de Benford seja melhorada. Porém se fossem calculados os votos do vencedor e a soma de todos as “outras opções,” tanto a amostra quanto a amplitude poderiam ser melhorados. Ou seja, a forma como dados são codificados pode afetar a qualidade da aproximação à Lei de Benford.
Sob essas condições descritas acima, temos então que a probabilidade de um número ter o primeiro dígito \(d={1,2,...,9}\) é dada por:
\[P(dígito\ inicial\ =\ d) = \log_{10}\left(\frac{d+1}{d}\right).\]
Para que a lei seja válida para um conjunto de dados na prática, é necessário fazer algumas suposições. Em primeiro lugar, é necessário ter um conjunto de dados razoavelmente grande. A Lei de Benford é assintótica, o que quer dizer que ela vale quando consideramos uma quantidade muito grande de números, se aproximando do infinito. Em termos práticos, qualquer conjunto de números é finito, e por isso seu comportamento será apenas uma aproximação da lei. Ou seja, podem haver divergências entre a distribuição empírica dos dados e o comportamento teórico esperado porque não está sendo considerada uma quantidade suficientemente grande de dados. Quanto mais números forem analisados, melhor será a aproximação.
Em segundo lugar, os números observados devem percorrer várias ordens de grandeza. Ou seja, os dados na sua amostra devem conter tanto números pequenos, na casa dos milhares, quanto números grandes, na casa dos milhões. Existem números inteiros positivos infinitamente grandes, porém em termos práticos números na ordem de dezenas de milhões geralmente já são suficientes para que o comportamento desses dados seja aproximado ao esperado pela Lei de Benford. Quanto maior for a amplitude de números observados, melhor será essa aproximação.
A Lei de Benford é utilizada para detectar fraudes porque números gerados de maneira artificial provavelmente não se comportarão como esperado pela Lei de Benford. A expectativa é que ao se alterar a quantidade de votos que seriam observados naturalmente, o processo gerador dos votos deixa de ser natural, tendo características que distorcem a quantidade de vezes que cada dígito aparece em primeiro lugar.
Nessa seção avaliamos se o número de votos do candidato vencedor da eleição, por município, respeita a Lei de Benford. Hoje em dia existem 5570 municípios no Brasil, com o número de habitantes variando entre 805 e 11.253.503. Ou seja, o comportamento do primeiro dígito do número de pessoas residentes nos municípios do Brasil deve ser bem aproximado ao que seria previsto pela Lei de Benford, pois temos uma amostra de tamanho razoável e a quantidade de pessoas residentes variam bastante. Como nessa seção vamos considerar votos no candidato que venceu a eleição, o limite superior será menor, entre 5 e 7 milhões, porém ainda é grande o suficiente para que a Lei de Benford seja aplicável.
Na figura 3 calculamos o percentual de vezes que cada dígito aparece em primeiro lugar, para o número total de votos do candidato a presidência em cada combinação de ano e turno da eleição. A linha vermelha representa o percentual teoricamente esperado de acordo com a Lei de Benford, e as barras em amarelo representam os percentuais observados em cada votação. Existem algumas discrepâncias, porém entre 2002 e 2018 os resultados têm um comportamento bastante parecido com aquele que seria esperado. Talvez a divergência mais perceptível é que em quase todas as votações, o percentual do número de votos municipais que começa com o dígito um é menor do que o esperado. Apesar dessa discrepância, meu feeling é que a divergência ocorre porque temos pouquíssimas cidades onde o candidato vencedor conseguiu mais do que 1 milhão de votos.
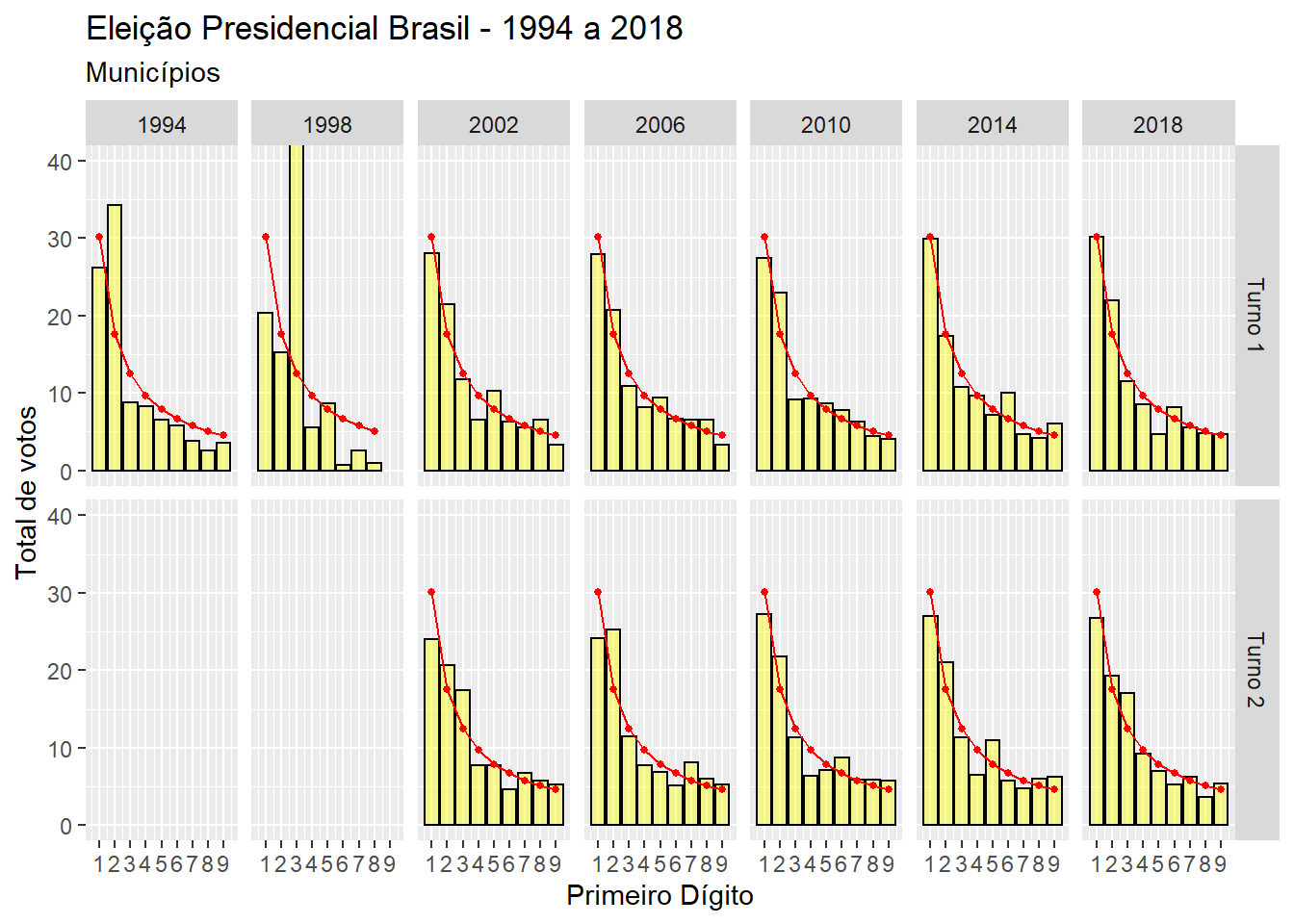
Figure 3: Gráfico mostrando as frequências observadas e esperadas do primeiro dígito (voto do vencedor)
Gráfico Fingerprint
No código abaixo, os dados são consolidados por município. Não mostrarei como baixar os dados do site do TSE, porém os dados consolidados podem ser baixados direto do site do PollingData.
require(tidyverse)
dir = tempdir()
#código baixando os dados do site do PollingData
url <- "http://www.pollingdata.com.br/blog/fraude brasil - 22-11-2019/mun_94_18.rds"
file.data = tempfile(tmpdir=dir, fileext=".rds")
download.file(url,file.data,method="curl")
df.benford <- readRDS(file.data)
df.ben <- df.benford %>% select(-votos) %>% rename(votos=votos_winner)
df.ben$turno <- paste0("Turno ",df.ben$turno)
df.ben$digit <- as.integer(str_sub(df.ben$votos,1,1))
df.ben <- df.ben %>% group_by(ano,turno,digit) %>%
summarise(
municipios=n(),
votos=sum(votos)
)
df.ben <- df.ben %>% mutate(pct=round(100*votos/sum(votos),1))
df.ben$benford <- round(100*log((df.ben$digit+1)/df.ben$digit,base = 10),1)
gg.ben <- ggplot(data=df.ben,aes(x=digit)) +
geom_bar(aes(y=pct),stat = "identity",fill="yellow",colour="black",size=0.5,alpha=0.4) +
geom_line(aes(y=benford),colour="red",size=0.5) +
geom_point(aes(y=benford),colour="red",size=1) +
facet_grid(turno~ano)
gg.ben <- gg.ben + scale_x_continuous(breaks=1:9) + scale_y_continuous(breaks=seq(0,100,by = 10))
gg.ben <- gg.ben + coord_cartesian(ylim = c(0, 40))
gg.ben <- gg.ben + labs(title = "Eleição Presidencial Brasil - 1994 a 2018", subtitle="Municípios") +
ylab("Total de votos") + xlab("Primeiro Dígito")
gg.benO mesmo não é verdade para os anos de 1994 e 1998. Nesses dois anos, os dados não têm o comportamento esperado. Uma vez que sabemos que esses dados estão incompletos, não é necessário se preocupar com fraude. Porém fica claro que esse indicador consegue detectar quando os números não foram gerados de maneira natural.
Conclusão
Não parecem haver evidências estatísticas de fraude nas eleições do Brasil, pelo menos no que se refere aos tipos de fraude descritas aqui. Mas fica claro que muitas vezes não é suficiente apenas conseguir aplicar um indicador, é necessário também entender porque ele funciona. Caso contrário, os resultados podem ser mal interpretados.
Apesar das análises apresentadas aqui não detectarem fraude, existem outros indicadores que poderiam ser utilizados. Um dos fatores mais importantes pra dificultar a fraude em eleições com cédulas fisicas é a logística. A geografia de um país pode complicar bastante a execução de fraudes eleitorais. Porém na votacão eletrônica, como usado no Brasil, as distâncias não importam, e a questão da logística desaparece. Se houver evidência de fraude nesse tipo de eleição, ela pode não estar nos dados das votações, mas no código do sistema operacional utilizado pelas urnas eletrônicas.
Eu acredito que a (nossa) democracia merece ser protegida; mas para isso, temos que entender como as fraudes podem ocorrer e como podem ser evitadas. E esse é um trabalho contínuo, pois fraudes podem se adaptar a qualquer mecanismo criado para evitá-las. É como o vírus de computador e o anti-vírus, eternamente brincando de pega-pega. Claramente, uma eleição é de extrema importância em uma democracia. Porém talvez a contagem dos votos seja ainda mais importante. Como disse o famoso ditador russo Joseph Stalin sobre uma votação do Partido Comunista em 1923:
“Eu considero totalmente sem importância quem do partido votará, ou como; mas o que é extraordinariamente importante é isso: quem vai contar os votos, e como.”
Referências
Apesar dessa lei receber o nome de Benford, a primeira pessoa a perceber que números se comportavam dessa maneira na natureza foi o astrônomo americano Simon Newcomb.↩︎