
Existe "evidência" de fraude na eleição presidencial da Bolívia?
By Neale Ahmed El-Dash on Oct 25, 2019
Nesse post discutiremos a eleição presidencial boliviana e as possíveis fraudes sendo denunciadas pela Organização dos Estados Americanos (OEA) e pela oposição do atual presidente Evo Morales. Analisaremos os resultados das pesquisas eleitorais bolivianas e também dados da eleição, utilizando algumas análises estatísticas para tentar detecar possíveis fraudes na eleição.
Introdução
No domingo passado, dia 20 de outubro, foi realizado o primeiro turno da eleição presidencial na Bolívia. Antes da realização da eleição em si, havia muita polêmica a respeito da candidatura do atual presidente Bolíviano Evo Morales, que concorre ao seu quarto mandato consecutivo. De acordo com a constituição boliviana, promulgada em 2009, um candidato só pode se reeleger uma vez. Em 2014, a participação de Evo Morales na disputa eleitoral foi permitida pois ele argumentou que como havia sido eleito pela primeira vez antes de 2009, sua primeira eleição não deveria ser considerada. Já em 2019, o argumento utilizado para autorizar sua candidatura foi de que se não fosse permitido à ele concorrer ao cargo seriam feridos os seus direitos humanos, visto que a Declaração Universal dos Direitos Humanos estabelece que todo cidadão tem o direito de concorrer a cargos públicos.
Após o encerramento das urnas no último domingo, os votos começaram a ser contabilizados. Com 83% dos votos apurados, o candidato Evo Morales liderava a disputa com 45% dos votos validos. Em segundo lugar, estava o candidato Carlos Mesa, com 38% dos votos validos. Se esse cenario se mantivesse ate o final da contagem, haveria segundo turno da eleição presidencial boliviana pela primeira vez na historia do pais. Na Bolívia, o segundo turno não ocorre em dois casos: se algum candidato consegue mais de 50% dos votos validos, ou se o candidato em primeiro lugar tem 40% ou mais dos votos validos e uma vantagem maior do que 10% em relação ao segundo colocado.
Faltando pouco mais de 15% dos votos a serem apurados, a contabilizacão dos votos foi paralizada. O governo boliviano justificou a paralizacão afirmando que um erro ocorreu na apuração. A alegacão foi que duas apurações estavam sendo realizadas em paralelo, uma levando em consideracão as atas das mesas de votação, com os resultados sendo divulgados nesse site e a outra a contagem dos votos em si. A posição oficial do governo era que a paralizacão ocorreu porque haviam divergências entre as duas contagens, porém não era de conhecimento público que haviam duas contagens distintas.
Após essa paralização, candidatos da oposição e diversas entidades, como a Organização dos Estados Americanos (OEA) manifestaram preocupacão com relacão a fraude na eleição. A OEA chegou a afirmar que a melhor opção para o país seria realizar o segundo turno por causa das suspeitas de fraude. Por sua vez, o atual presidente Evo Morales disse que as denúncias eram na verdade uma tentativa de golpe de estado da oposição.
O objetivo desse post é analisar os dados disponíveis, numa tentativa de avaliar se é possivel detectar anomalias estatísticas tipicamente presentes em eleições fraudadas. Os dados utilizados serão tantos os resultados publicados de pesquisas eleitorais, quanto os da contagem parcial dos votos.
Para não haver dúvidas sobre o objetivo desse post, é importante definir o significado de evidência. De forma geral, evidência é qualquer informação apresentada para apoiar uma afirmação. Esse apoio pode ser forte ou fraco. A evidência mais forte é aquela que provê prova direta de que a afirmação é verdadeira. No outro extremo, estão as evidências que são meramente consistentes com a afirmação, porém não eliminam outras afirmações contraditórias. No título desse post, a palavra “evidência” está entre aspas porque estou falando de evidência estatística. Nesse contexto, evidência significa características peculiares nos dados do resultado da eleição, as quais poderiam ser explicadas por fraudes eleitorais. Esse tipo de evidência não prova diretamente a existência de fraude, porém pode ser muito útil para apontar outras evidências, mais fortes.
As pesquisas eleitorais
O site Polling Data faz previsão dos resultados de eleições utilizando pesquisas eleitorais públicas há mais de 5 anos. Utilizamos um modelo simples porém eficiente, que leva em consideração o viés metodológico de cada instituto de pesquisa, a data que a pesquisa foi realizada, o tamanho da amostra e quanto tempo falta até a eleição. Para quem tiver interesse, nesse link é possivel obter mais informações sobre o modelo utilizado.
Apesar do site ter uma estimativa default para a eleição boliviana, bem como para todas as eleições nacionais com pesquisas publicadas no wikipedia, fizemos uma versão customizada para esse post. Dois motivos principais motivaram a utilização dessa versão especial do modelo. Primeiramente o site utiliza, como padrão, as pesquisas publicadas na versão do wikipedia em língua inglesa, porém para essa eleição a versão em espanhol do wikipedia tem resultados de mais pesquisas. Em segundo lugar, nesse post estamos interessados na probabilidade de haver segundo turno. Além dessa probabilidade não ser calculada automaticamente pelo site, no caso da eleição boliviana, as condições para ocorrência do segundo turno são mais complexas do que usualmente ocorre em outros paises.
Na figura 1 abaixo mostramos o modelo do Polling Data aplicado as pesquisas eleitorais do primeiro turno da eleição boliviana. As estimativas de votos válidos são de 44% para Evo Moralez e de 31% para o Meso. Além disso, a probabilidade estimada de haver segundo turno é de 34%. Apesar de ser uma probabilidade alta, é ainda mais provavel não haver segundo turno. De acordo com as pesquisas, tanto a ocorrência do segundo turno quanto a vitória de Evo Morales no primeiro turno são eventos bastante prováveis. Assim, usando apenas os dados de pesquisas eleitorais, não existe evidência de fraude eleitoral. Inclusive, a disputa entre os dois principais candidatos está bem mais acirrada na eleição do que seria esperado.
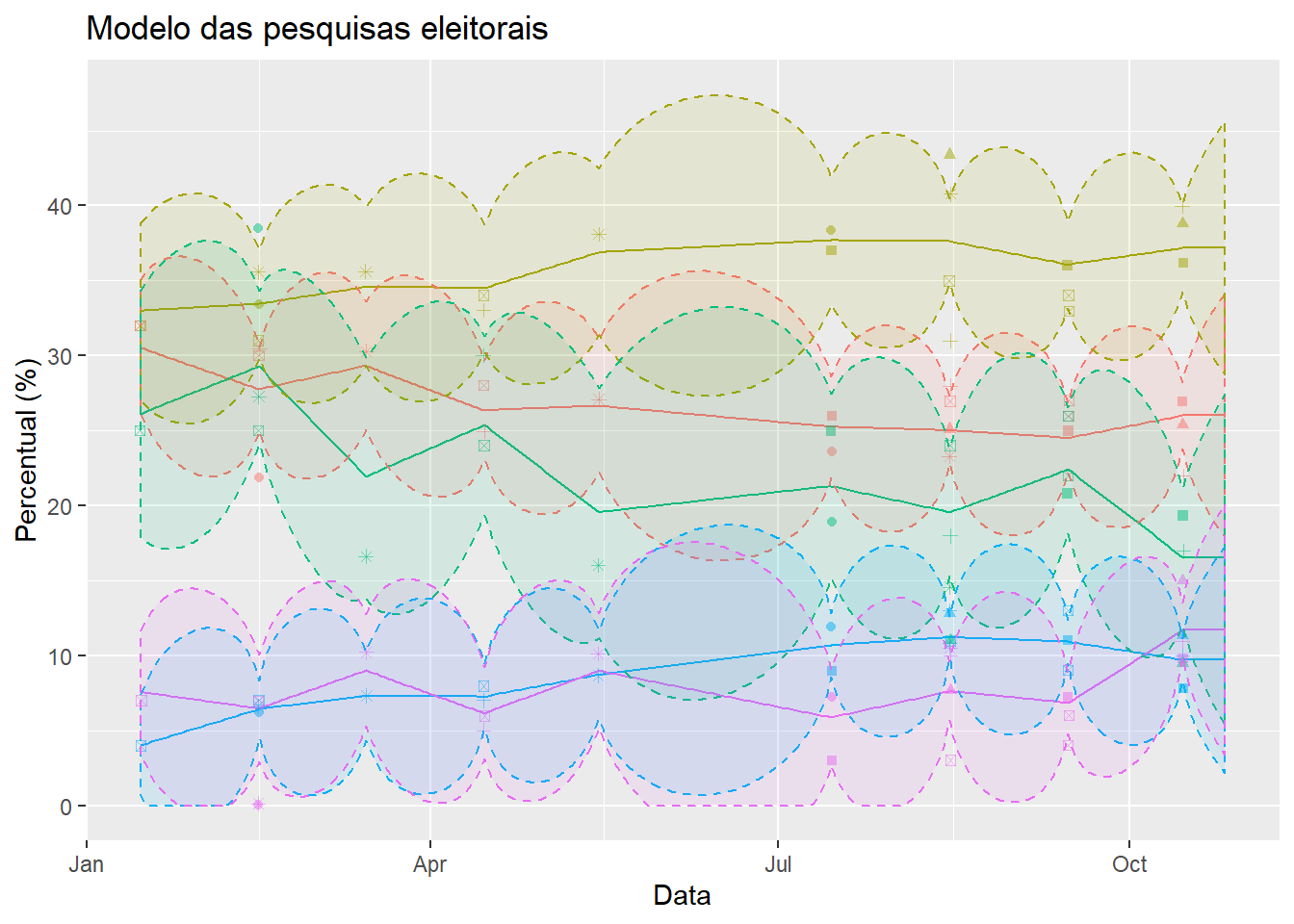
Figure 1: Pesquisas Eleitorais bolivianas em 2019
Dados das pesquisas
Nessa seção não mostrarei como rodar o modelo do Polling Data nem a geração do gráfico. Mostrarei apenas como baixar os dados de todas as pesquisas da versão em espanhol do Wikipedia. Não me preocupei em extrair as url’s específicas de cada pesquisa pois essa informação não será utilizada nesse post. Grande parte das formatações realizadas na base de dados são motivadas pelas funções que eu já desenvolvi para rodar o modelo do polling data, as quais esperam que a base de dados de pesquisa esteja num formato específico.
require(rvest)
require(tidyverse)
require(lubridate)
################
## Wikipedia Espanhol
url <- "https://es.wikipedia.org/wiki/Anexo:Encuestas_de_intenci%C3%B3n_de_voto_para_las_elecciones_generales_de_Bolivia_de_2019"
#pesquisas
pag <- read_html(url)
tabs <- pag %>% html_table(fill=TRUE)
tab <- tabs[[2]]
#limpando base
tab <- tab[-1,]
tab <- tab[,1:14]
nomes <- c("Instituto", "Fuente", "Data", "Morales", "Mesa", "Ortiz",
"Paz", "Cardenas", "Patzi", "Lema", "Nina", "Rodríguez", "Brancos",
"NS/NR")
tab <- tab[-1,]
names(tab) <- nomes
tab <- tab[c(-9,-10),]
tab <- tab[1:25,]
tab$Fuente <- NULL
tab$Brancos <- NULL
tab$`NS/NR` <- NULL
tab$Instituto <- str_squish(str_replace_all(tab$Instituto,"\\(.*\\)$",""))
tab <- tab %>% mutate(
aux.data = str_extract(Data,"^[^-]*"),
Data = case_when(
aux.data == 'Enero' ~ as.Date("2019-01-15"),
aux.data == 'Febrero' ~ as.Date("2019-02-15"),
aux.data == 'Marzo' ~ as.Date("2019-03-15"),
aux.data == 'Abril' ~ as.Date("2019-04-15"),
aux.data == 'Mayo' ~ as.Date("2019-05-15"),
aux.data == 'Julio' ~ as.Date("2019-07-15"),
aux.data == 'Agosto' ~ as.Date("2019-08-15"),
aux.data == 'Septiembre' ~ as.Date("2019-09-15"),
aux.data == 'Octubre' ~ as.Date("2019-10-15")
)
) %>% select(-aux.data)
tab <- tab %>% mutate_at(vars(-Instituto,-Data),list(~str_replace(.,",",".")))
tab <- tab %>% mutate_at(vars(-Instituto,-Data),list(~as.numeric(str_replace(.,"%",""))))
tab$Entrevistas <- 1000
tab$erro <- NA
tab$registro <- NA
tab$link <- url
tab <- tab %>% select(Instituto,Data,Entrevistas,everything())Os resultados da eleição
A outra fonte de dados disponível para análise são os resultados da votação, agregados no nível das mesas eleitorais. No Brasil, as mesas seriam o equivalente às seções eleitorais. O nível hierárquico superior são os recintos, que são equivalentes as zonas eleitorais brasileiras. Com esses dados é possível calcular quantos votos cada candidato recebeu, e quantas pessoas comparareceram para votar, em cada um dos 5.022 recintos eleitorais, e em cada uma das 33.044 mesas eleitorais. Até o momento que escrevo esse post, esses dados são parciais, contendo pouco mais de 99% dos votos registrados na eleição boliviana.
Existem muitos estudos recentes discutindo como detectar fraudes via anomalias estatísticas nos resultados de eleições. Esses estudos descrevem os tipos de fraudes consideradas, e quais as consequências mensuráveis nos resultados. As anomalias consideradas aparecem em diferentes aspectos dos resultados. Os números dos resultados de eleições, agregados em níveis geográficos que têm grande variação de ordens de grandeza, como por exemplo municípios, devem se comportar como números aleatórios e por isso respeitar a lei de Benford1. Assim, a não conformidade com essa lei é vista como existência de fraude.
Em outros tipos de fraude, as anomalias são detectadas nos percentuais de voto. Por exemplo, uma incidência maior do que esperada em percentuais divisíveis por cinco (por exemplo 20%, 50%, 55% ou 60%) também é um indicativo de fraude. Testes estatísiticos, como o descrito nesse artigo (Rozenas 2017) foram desenvolvidos para avaliar a freqüência relativa desses percentuais.
Uma outra estratégia diferente para detectar sinais de fraude eleitoral é analisar a distribuição de votos e do comparecimento dos eleitores. Dois tipos de fraude podem ser detectadas utilizando esse tipo de análise: a adição de votos falsos para um candidato nas urnas, ou a substituição dos votos de um candidato para outro. Esses mecanismos de fraude produzem algumas características peculiares nos resultados das eleições, características essas que dificilmente ocorrem em eleições justas.
A fraude de adicionar votos em urnas pode ser incremental ou extrema: poucos votos para o candidato beneficiado adicionados em muitas urnas, ou muitos votos adicionados a poucas urnas, respectivamente. Geralmente a opção por qual estratégia adotar está relacionada a questões logísticas. Por um lado, espalhar os votos fraudulentos em mais locais pode ser menos óbvio, porém necessita do envolvimento de mais conspiradores. Concentrar os votos em menos locais pode gerar anomalias mais extremas, porém potencialmente produz menos testemunhas. Como o limite de votos a ser adicionado numa urna é o total de eleitores registrados naquele local, estas estratégias induzem uma correlação forte entre o percentual de votos do candidato ganhador com o percentual de comparecimento de eleitores. Esse artigo (Klimek et al. 2012) discute em detalhes análises estatísticas que podem ser realizadas para detectar estas fraudes, e compara os resultados de eleições em diferentes países com o objetivo de identificar fraudes eleitorais.
Por mais que seja possível detectar essa características em eleições sem fraude, quanto mais eleitores forem registrados num local, mais raro é que este local apresente essas anomalias. Em áreas muito pequenas, essas anomalias podem ocorrer naturalmente, com a quase totalidade dos votos favoráveis ao vencedor ou abstencão quase nula. Porém, em locais maiores, por exemplo com mais de 100 eleitores, é difícil acreditar que todos os eleitores compareceram e votaram no mesmo candidato. Essas características foram procuradas na votação da Bolívia. A análise foi realizada no nível das mesas (menores) e também no nível dos recintos (maiores). Além disso, em ambos os casos, na análise também retiramos locais com menos de 100 eleitores registrados. Nos quatro cenários descritos, os resultados foram similares. Ou seja, os resultados são consistentes, independente da hierarquia e dos tamanhos dos locais de votação.
Nesse post nos limitaremos a fazer apenas uma análise exploratória dos dados, identificando visualmente mesas eleitorais que têm as anomalias descritas acima: alto percentual de voto para o candidato vencedor, e alto percentual de comparecimento. Na figura 2 mostramos os resultados para todas as mesas eleitorais. As anomalias mais extremas, descritas acima, são destacadas no gráfico, dentro do retângulo vermelho. Não é tão fácil enxergar nesse gráfico, porém algumas combinações extremas ocorrem frequentemente.
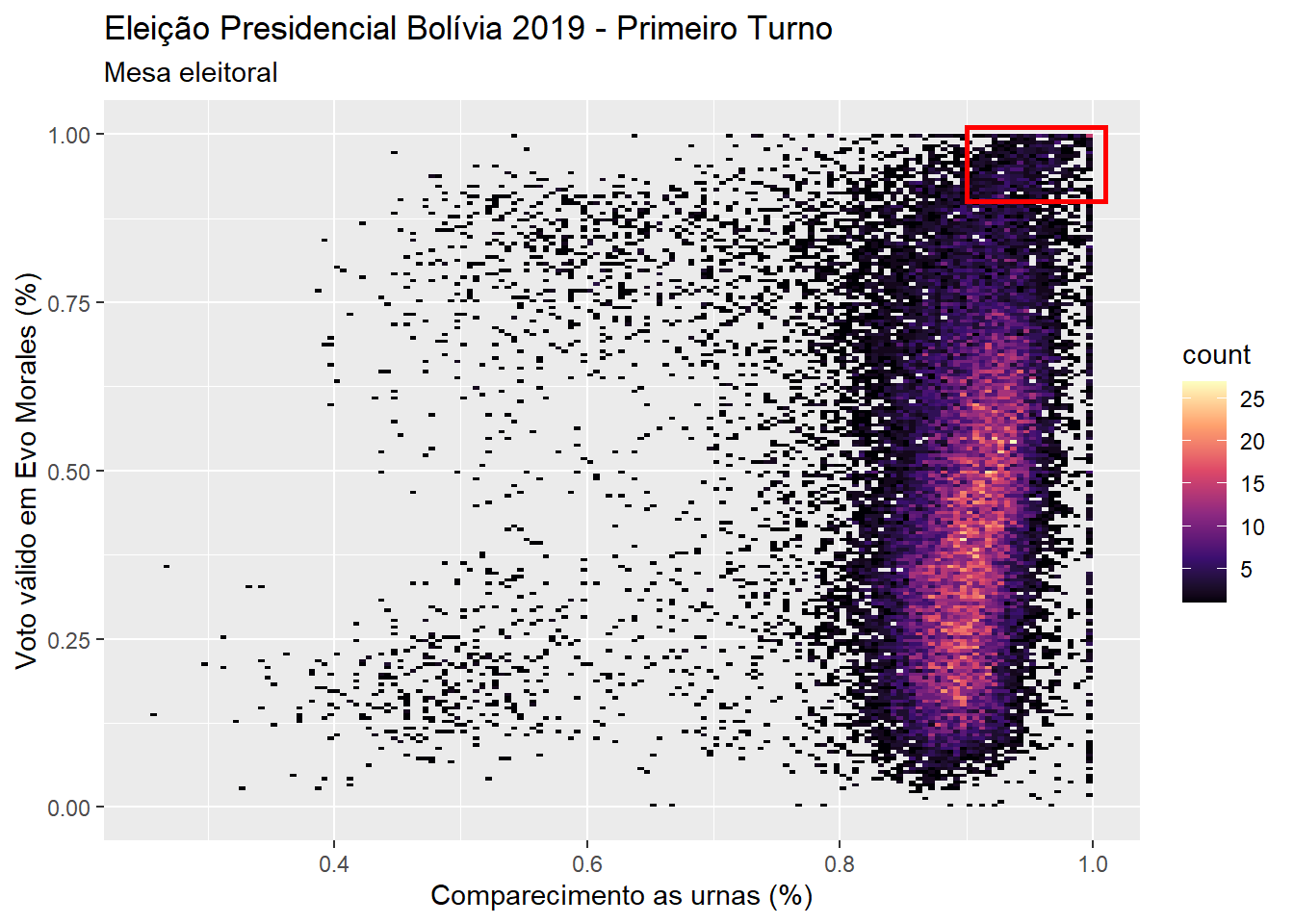
Figure 2: Gráfico mostrando a relação entre comparecimento as urnas e voto válido
Gráfico das anomalias
Como os dados consolidados por mesa da eleição boliviana podem ser alterados, no código abaixo estou baixando os dados do servidor do Polling Data, para que a análise realizada no código abaixo reproduza exatamente os resultados publicados no post, porém os dados originais podem ser baixados no link denominado de Actas localizado no site oficial da apuração dos resultados.
require(tidyverse)
dir = tempdir()
#código baixando os dados do site do PollingData
url <- "http://www.pollingdata.com.br/blog/fraude eleitoral bolivia - 10-23-2019/df_mesa.rds"
file.data = tempfile(tmpdir=dir, fileext=".rds")
download.file(url,file.data,method="curl")
df.bo <- readRDS(file.data)
df.mesa <- df.bo %>% mutate(
tipo = ifelse(pais == "Bolivia","Bolivia","Exterior"),
voto_valido = CC+FPV+MTS+UCS+`MAS - IPSP`+`21F`+PDC+MNR+`PAN-BOL`,
check = abs(voto_valido - voto_valido_check),
votos = voto_valido+brancos+nulos,
voto_evo = `MAS - IPSP`,
turnout=votos / pop,
winner=voto_evo / voto_valido,
N = pop,
V = voto_valido,
W = voto_evo / V,
T = votos / pop
)
#df.mesa <- df.mesa %>% filter(pop >= 100)
gg <- ggplot(data=df.mesa) +
geom_bin2d(aes(x=turnout,y=winner),bins = 200) +
scale_fill_viridis_c(option = "A")
gg <- gg + geom_rect(xmin=0.90, xmax=1.01, ymin=0.9, ymax=1.01, fill=NA, color="red", size=1)
gg <- gg + labs(title = "Eleição Presidencial Bolívia 2019 - Primeiro Turno", subtitle="Mesa eleitoral") +
ylab("Voto válido em Evo Morales (%)") + xlab("Comparecimento as urnas (%)")
ggComo benchmark externo, no artigo mencionado acima, o autor fez um gráfico similar ao gráfico 2, porém comparando o resultado de eleições em diversos países. Nesse gráfico, desenhado abaixo, as mesmas características podem ser vistas nas eleições da Rússia e de Uganda. Em ambos os casos acredita-se que houveram fraudes eleitorais. As anomalias também estão destacadas nesse gráfico. Note que não estamos falando somente do limite superior direito, mas do fato da núvem de pontos parecer ser atraída para esse extremo.
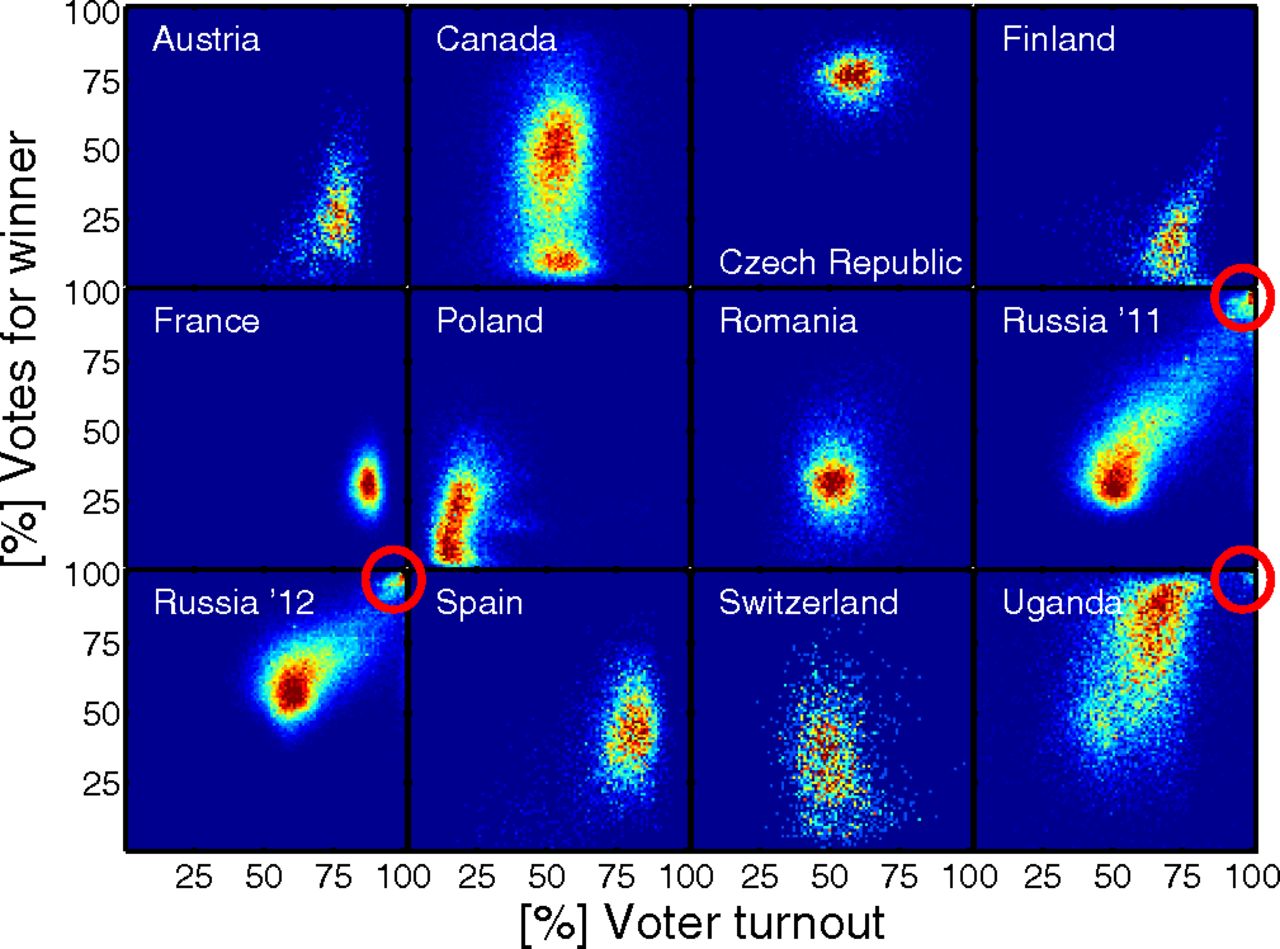
Uma análise interessante de ser feita é avaliar o que ocorre com o resultado da eleição ao excluir, progressivamente, os locais com maior chance de serem classificados como fraude. Ou seja, ao retirar os locais com percentuais de voto para o candidato vencedor e percentual de comparecimento muito extremos, o resultado da eleição é alterado? Criamos vários pontos de corte, excluindo os votos em locais com o mesmo percentual de voto e comparecimento extremos. Na tabela 1 mostramos os cenários excluindo locais com 100% de comparecimento e voto para Evo, depois com 99% ou mais, e assim sucessivamente até 90%. A linha destacada com cinza é o resultado da eleição com todos os votos, mostrando que nesse cenário não haveria segundo turno. A linha destacada em laranja é o primeiro cenário onde ao excluir as áreas mais suspeitas, a eleição teria outro resultado, havendo segundo turno. Ou seja, retirar os 100 recintos mais suspeitos, que representam apenas 62.000 votos, é suficiente para mudar o resultado desta eleição.
| Cenário |
Recintos Excluídos |
Votos Excluídos |
% votos Excluídos |
Votos Válidos |
Votos Evo |
Votos Meso |
% Votos Evo |
% Votos Meso |
% Vantagem Evo |
Resultado |
|---|---|---|---|---|---|---|---|---|---|---|
| Total de Votos | 0 | 0 | 0% | 6.137.229 | 2.889.074 | 2.240.894 | 47.07% | 36.51% | 10.56% | Vitoria Evo |
| Corte 100% | 1 | 26 | 0% | 6.137.203 | 2.889.048 | 2.240.894 | 47.07% | 36.51% | 10.56% | Vitoria Evo |
| Corte 99% | 12 | 2.800 | 0.05% | 6.134.429 | 2.886.299 | 2.240.892 | 47.05% | 36.53% | 10.52% | Vitoria Evo |
| Corte 98% | 20 | 5.391 | 0.09% | 6.131.838 | 2.883.739 | 2.240.888 | 47.03% | 36.55% | 10.48% | Vitoria Evo |
| Corte 97% | 41 | 14.090 | 0.23% | 6.123.139 | 2.875.186 | 2.240.865 | 46.96% | 36.6% | 10.36% | Vitoria Evo |
| Corte 96% | 68 | 37.184 | 0.61% | 6.100.045 | 2.852.881 | 2.240.659 | 46.77% | 36.73% | 10.04% | Vitoria Evo |
| Corte 95% | 100 | 62.420 | 1.02% | 6.074.809 | 2.828.573 | 2.240.441 | 46.56% | 36.88% | 9.68% | Turno2 |
| Corte 94% | 135 | 77.548 | 1.26% | 6.059.681 | 2.814.211 | 2.240.224 | 46.44% | 36.97% | 9.47% | Turno2 |
| Corte 93% | 179 | 97.771 | 1.59% | 6.039.458 | 2.795.190 | 2.239.904 | 46.28% | 37.09% | 9.19% | Turno2 |
| Corte 92% | 231 | 125.727 | 2.05% | 6.011.502 | 2.769.079 | 2.239.393 | 46.06% | 37.25% | 8.81% | Turno2 |
| Corte 91% | 285 | 141.416 | 2.3% | 5.995.813 | 2.754.598 | 2.239.129 | 45.94% | 37.34% | 8.6% | Turno2 |
| Corte 90% | 353 | 183.220 | 2.99% | 5.954.009 | 2.716.758 | 2.237.854 | 45.63% | 37.59% | 8.04% | Turno2 |
Tabela com cenários
No código abaixo, os dados são consolidados por recinto. Além disso, também criamos os diferentes cortes para os cenários, e agregamos os resultados finais na tabela publicada. Todo o código abaixo poderia ser otimizado, tanto no sentido de ser escrito de forma mais rápida, quanto de ser mais facilmente entendido por outras pessoas, porém não houve tempo hábil para isso antes de publicar o post.
require(knitr)
require(kableExtra)
df.recinto <- df.bo %>% group_by_at(vars(-num_mesa,-cod_mesa,-pop,-CC,-FPV,-MTS,-UCS,-`MAS - IPSP`,-`21F`,-PDC,-MNR,-`PAN-BOL`,-voto_valido_check,-brancos,-nulos)) %>%
summarise_at(vars(pop,CC,FPV,MTS,UCS,`MAS - IPSP`,`21F`,PDC,MNR,`PAN-BOL`,voto_valido_check,brancos,nulos),
list(~sum(.,na.rm = TRUE)))
df.recinto <- df.recinto %>% ungroup() %>% mutate(
tipo = ifelse(pais == "Bolivia","Bolivia","Exterior"),
voto_valido = CC+FPV+MTS+UCS+`MAS - IPSP`+`21F`+PDC+MNR+`PAN-BOL`,
check = abs(voto_valido - voto_valido_check),
votos = voto_valido+brancos+nulos,
voto_evo = `MAS - IPSP`,
turnout=votos / pop,
winner=voto_evo / voto_valido,
N = pop,
V = voto_valido,
W = voto_evo / V,
T = votos / pop
)
#df.recinto <- df.recinto %>% filter(pop >= 100,tipo == "Bolivia")
df.fraude <- df.recinto
df.fraude <- df.fraude %>% arrange(desc(winner)) %>% mutate(
corte_winner = round(100*cummin(winner),0)
)
df.fraude <- df.fraude %>% arrange(desc(turnout)) %>% mutate(
corte_turnout = round(100*cummin(turnout),0)
)
df.fraude <- df.fraude %>% mutate(
corte.90 = ifelse(corte_winner >= 90 & corte_turnout >= 90,0,1),
corte.91 = ifelse(corte_winner >= 91 & corte_turnout >= 91,0,1),
corte.92 = ifelse(corte_winner >= 92 & corte_turnout >= 92,0,1),
corte.93 = ifelse(corte_winner >= 93 & corte_turnout >= 93,0,1),
corte.94 = ifelse(corte_winner >= 94 & corte_turnout >= 94,0,1),
corte.95 = ifelse(corte_winner >= 95 & corte_turnout >= 95,0,1),
corte.96 = ifelse(corte_winner >= 96 & corte_turnout >= 96,0,1),
corte.97 = ifelse(corte_winner >= 97 & corte_turnout >= 97,0,1),
corte.98 = ifelse(corte_winner >= 98 & corte_turnout >= 98,0,1),
corte.99 = ifelse(corte_winner >= 99 & corte_turnout >= 99,0,1),
corte.100 = ifelse(corte_winner >= 100 & corte_turnout >= 100,0,1),
corte.101 = ifelse(corte_winner >= 101 & corte_turnout >= 101,0,1),
)
df.lista <- df.fraude %>% filter(corte.98 == 0) %>% arrange(desc(`MAS - IPSP`))
df.fraude <- df.fraude %>% select(starts_with("corte."),votos,voto_valido,turnout,`MAS - IPSP`,CC)
df.fraude <- df.fraude %>% gather(corte,val,starts_with("corte."))
df.fraude <- df.fraude %>% filter(val == 1)
tot.recintos <- nrow(df.recinto)
df.fraude <- df.fraude %>% group_by(corte) %>% summarise(
voto_valido=sum(voto_valido),
evo = sum(`MAS - IPSP`),
mesa = sum(CC),
recintos.excluidos = tot.recintos - n()
)
tot.vot <- sum(df.recinto$voto_valido)
df.fraude <- df.fraude %>% ungroup() %>% mutate(
votos.excluidos = tot.vot - voto_valido,
perc.excluidos = votos.excluidos / tot.vot,
corte.val = as.numeric(str_extract(corte,"[0-9]{1,3}")),
p.evo = evo / voto_valido,
p.mesa = mesa / voto_valido,
dif = p.evo - p.mesa,
result = ifelse(p.evo > 0.5 | (p.evo > 0.4 & (p.evo-p.mesa) > 0.1),"Vitoria Evo","Turno2")
) %>% arrange(desc(corte.val))
df.fraude <- df.fraude %>% select(corte.val,ends_with('excluidos'),voto_valido, evo, mesa,p.evo,p.mesa,dif,result)
df.fraude$corte.val <- paste0("Corte ",df.fraude$corte.val,"%")
df.fraude$corte.val[1] <- "Total de Votos"
df.fraude <- df.fraude %>% mutate_at(vars(perc.excluidos,p.evo,p.mesa,dif),list(~paste0(round(100*.,2),"%")))
df.fraude <- df.fraude %>% mutate_at(vars(recintos.excluidos,votos.excluidos,voto_valido,evo,mesa),list(~format(.,digits = 0,big.mark = ".",decimal.mark = ",",scientific = FALSE)))
names(df.fraude) <- c('Cenário','Recintos<br>Excluídos','Votos<br>Excluídos','% votos<br>Excluídos','Votos<br>Válidos','Votos<br>Evo','Votos<br>Meso','% Votos<br>Evo','% Votos<br>Meso','% Vantagem<br>Evo','Resultado')
knitr::kable(df.fraude,
align=rep('c', ncol(df.fraude)),
escape = FALSE,
booktabs = TRUE,
caption = 'Cenários de fraude eleitoral.') %>%
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"),full_width = F, position = "center") %>%
#column_spec(1, width = "60px") %>%
#column_spec(4, background="darkorange", bold = T, color = "white") %>%
row_spec(1, bold = T, color = "white", background = "darkgray") %>%
row_spec(7, bold = T, color = "white", background = "darkorange")É importante ressaltar que detectar anomalias estatísticas nos resultados de eleições não é prova de fraude eleitoral. Porém essas análises podem auxiliar as autoridades na fiscalização das eleições, encorajando a busca de novas evidências nos locais destacados como tendo maior chance de fraude. Para comprovar fraude, é necessário encontrar evidências fortes, nos locais de votação, que demonstrem se uma fraude foi de fato cometida, e como isso foi feito.
Conclusão
Muitas críticas já foram feitas com relacão às pesquisas eleitorais, e indiretamente ao papel do estatístico na sociedade. Será que as pesquisas medem a intenção de voto da população, ou será que elas alteram o voto da população, que as utiliza para exercer um voto útil? Não existem evidências muito fortes a respeito do tema, porém parece claro que mesmo que as pesquisas não tenham um efeito direito, indiretamente afetam as campanhas dos candidatos, tanto no aspecto do otimismo da equipe quanto no aspecto financeiro ao aumentar a chance de doações. Para o leitor mais interessado no assunto, leia o terceiro capítulo da minha tese de doutorado.
O caso de fraudes eleitorais é um exemplo claro da importância da estatística para a sociedade. Ela não somente pode adjudar o país a enxergar o caminho para o futuro, como também pode protegê-lo de fraudes em eleições, as quais são fundamentais para que um governo democrático continue a representar o desejo da maioria da população. O uso regular de estatísticas como essas mostradas na seção anterior, por orgãos nacionais reponsáveis pelas eleições, pode ser importante para garantir uma eleição justa. Porém ao fazer isso, é possível argumentar que estaremos ajudando o mecanismo de fraude a evoluir, para que no futuro outras fraudes, mais sofisticadas, possam ser cometidas sem gerar as anomalias estatísticas discutidas aqui.
Um dos fatores mais importantes pra dificultar a fraude em eleições com cédulas fisicas é a logística. A geografia de um país pode complicar bastante a execução de fraudes eleitorais. Porém na votacão eletrônica, como usado no Brasil, as distâncias não importam, e a questão da logística desaparece. Se houver evidência de fraude nesse tipo de eleição, ela pode não estar nos dados das votações, mas no código do sistema operacional utilizado pelas urnas eletrônicas. Eu acredito que a nossa democracia merece ser protegida; mas para isso, temos que entender como as fraudes podem ocorrer e como podem ser evitadas. Com certeza, medidas preventivas devem existir, como nessa notícia, onde pesquisadores avaliam limitações de segurança das urnas eletrônicas brasileiras.
John Adams, que foi o primeiro vice-presidente e o segundo presidente americano, foi fundamental nas negociações de paz entre os Estados Unidos e a Inglaterra, após a Guerra da Independência. Num momento fundamental da história americana, ele escreveu um texto importante sobre democracia, sob um ponto de vista interessante, muito pertinente ao tema discutido nesse post:
“É em vão dizer que a democracia é menos vaidosa, menos orgulhosa, menos egoísta, menos ambiciosa, ou menos avarenta do que a monarquia ou a aristocracia. De fato não é verdade, e nunca foi dito em nenhum momento da História. Essas paixões são as mesmas em todos os homens, sob todas as formas de governo simples, e quando não são controladas, produzem os mesmos efeitos de fraude, violência e crueldade. Quando oportunidades claras de vaidade, orgulho, avarice ou ambição se apresentam, é impossível evitá-las por causa da gratificação instantânea. Até para os filósofos mais ponderados, ou os moralistas mais conscientes, é difícil resistir à tentação. Indivíduos conseguem se controlar. Porém nações e grandes grupos de homems, nunca.”
Referências
A Lei de Benford é explicada didaticamente nesse artigo (Fewster 2009).↩︎